
GPT
作者:365bet网页版 发布时间:2025-08-13 09:47
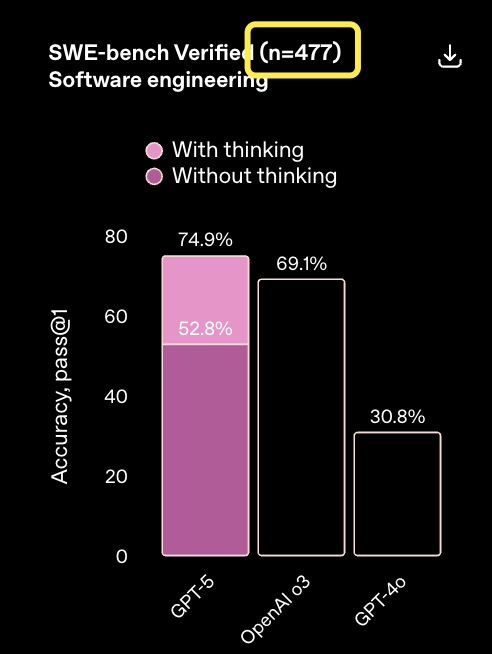 来自Aofeisi量子位的Bai Jiao |官方帐户QBITAI不会急于在该计划中使用GPT-5,也许其能力并不像您想象的那么强大。有些人发现经过验证的SWE板凳用于测试官方测试的编程功能,但该产品不正确,仅使用了477个问题。这是什么意思?我们知道,SWE基础是一个常见且常用的指标,用于审查模型/代理中的自主技能。作为已验证的SWE基础子集,总共有500个问题。现在,这相当于23个脱离了自己的问题。我创建了子集的子集以检查模型功能。如果这些问题默认为零,则标记实际上低于Claude Opus 4.1。因为今天有一个0.4%的差距。扩展全文
这并不是Openai首次自行忽略23个问题的操作。
早在GPT-4.1发行时,我发誓说我没有注意到的原因是解决这些问题的解决方案无法与他们的基础设施一起使用。
地图 - 吸引朋友!您应该知道,已经验证了Swe Bench的Openai由他自己建议。原因是SWE Bench无法系统地评估模型的编程能力,因此我决定自己精炼另一个子集。
现在,由于测试问题无法正常运行,因此我再次制作了一个“子集”子集。
我认为在GPT-5实时广播中看到图表错误是太多了,但是现在我告诉我这里的结果可能是假的?
AOF OpenAi已删除了23个问题
一些网民开始发现GPT-5功能并不比Claude 4.1 Opus更好。
今天,该官员提供的结果可能没有参考值。
除了忽略一些测试问题和“伪造结果”之外,网民还发现,他们将GPT-5与Opus 4.1的最大心理努力进行了比较,而没有扩展思维,并且仅依靠原始模型输出。这种比较真的毫无价值的参考。
他们仅使用477个问题尝试的原因与释放GPT-4.1时相同,因为他们的内部基础架构无法运行剩余的23个问题。
当GPT-4.1于今年4月发布时,比分为54.6%,同时使用了477个问题。
该官员还指出,如果这些问题的分数保守地设置为0,那么得分的54.6%将为52.1%。虽然,这个值是当时最高的。
在拟人化中,实际上发现了Openai操作。
当Claude Opus 4.1发布编程结果时,本文的末尾有一个句子。
对于Claude 4系列模型,我们将继续使用相同的简单图,其中仅使用两个工具用于该模型 - bash工具和通过替换字符串替换的文件编辑工具,并且不再包含Claude 3.7十四行诗中使用的第三个“计划工具”。
最后:在所有Claude 4模型中,他们报告的分数都是基于的在完整的500个问题上。根据477个问题的子集,报告了OpenAI模型标记。
基准仍然是功夫,OpenAi本身建议
如果经过Swe Bench是Openai建议的基准,那么这件事会更加生气。
这不等同于步行开枪吗?
当时,这是因为类似的原因。他们发现,某些SWE基础活动可能难以解决甚至无法解决,这导致SWE Bench无法系统地评估模型编程中的自主技能。
因此,他们决定与SWE-Bench作者合作,并决定创建一个新版本,希望提供更准确的审查。
他们一起启动了一个手动注释活动,共有93位高级程序员参与过滤每个SWE-Bench测试集样本,以获得一组适当的单位测试和明确定义的问题描述。
随机选择了1699个示例,然后被标记为基础D在标准上。
例如,对问题的描述清楚吗?每个注释都有一个标签,距[0、1、2、3],并在以下内容中增加了严重性。
标签0和1表示续集;标签2和3表示严重性,表明样本在某些方面存在缺陷,应丢弃。
此外,我们通过在开发人员确定和实施解决方案所需的时间估算评论员来评估每个示例的难度。
最后,获得了500个经过验证的样本,数据集是贫困的。 “简单”子集包含196个调整不到15分钟的任务,而“硬”子集包含45个超过1小时的活动。
结果,该子集再次减少了Openai。
另一个
但是,仍然有一个值得确定的列表,这是最原始的SWE板凳。
在此列表中,Claude 4 Opus仍然征服了领先优势。
GPT-5已发布了一段时间。我想知道你是否有E类似的编程经验?欢迎在评论部分中向我们致意。
参考链接:
[1] https://www.swebench.com/
[2] https://openai.com/index/introducing-pt-5/
[3] https://www.anththropic.com/news/claude-pus- 4-1回到Sohu,以查看更多
来自Aofeisi量子位的Bai Jiao |官方帐户QBITAI不会急于在该计划中使用GPT-5,也许其能力并不像您想象的那么强大。有些人发现经过验证的SWE板凳用于测试官方测试的编程功能,但该产品不正确,仅使用了477个问题。这是什么意思?我们知道,SWE基础是一个常见且常用的指标,用于审查模型/代理中的自主技能。作为已验证的SWE基础子集,总共有500个问题。现在,这相当于23个脱离了自己的问题。我创建了子集的子集以检查模型功能。如果这些问题默认为零,则标记实际上低于Claude Opus 4.1。因为今天有一个0.4%的差距。扩展全文
这并不是Openai首次自行忽略23个问题的操作。
早在GPT-4.1发行时,我发誓说我没有注意到的原因是解决这些问题的解决方案无法与他们的基础设施一起使用。
地图 - 吸引朋友!您应该知道,已经验证了Swe Bench的Openai由他自己建议。原因是SWE Bench无法系统地评估模型的编程能力,因此我决定自己精炼另一个子集。
现在,由于测试问题无法正常运行,因此我再次制作了一个“子集”子集。
我认为在GPT-5实时广播中看到图表错误是太多了,但是现在我告诉我这里的结果可能是假的?
AOF OpenAi已删除了23个问题
一些网民开始发现GPT-5功能并不比Claude 4.1 Opus更好。
今天,该官员提供的结果可能没有参考值。
除了忽略一些测试问题和“伪造结果”之外,网民还发现,他们将GPT-5与Opus 4.1的最大心理努力进行了比较,而没有扩展思维,并且仅依靠原始模型输出。这种比较真的毫无价值的参考。
他们仅使用477个问题尝试的原因与释放GPT-4.1时相同,因为他们的内部基础架构无法运行剩余的23个问题。
当GPT-4.1于今年4月发布时,比分为54.6%,同时使用了477个问题。
该官员还指出,如果这些问题的分数保守地设置为0,那么得分的54.6%将为52.1%。虽然,这个值是当时最高的。
在拟人化中,实际上发现了Openai操作。
当Claude Opus 4.1发布编程结果时,本文的末尾有一个句子。
对于Claude 4系列模型,我们将继续使用相同的简单图,其中仅使用两个工具用于该模型 - bash工具和通过替换字符串替换的文件编辑工具,并且不再包含Claude 3.7十四行诗中使用的第三个“计划工具”。
最后:在所有Claude 4模型中,他们报告的分数都是基于的在完整的500个问题上。根据477个问题的子集,报告了OpenAI模型标记。
基准仍然是功夫,OpenAi本身建议
如果经过Swe Bench是Openai建议的基准,那么这件事会更加生气。
这不等同于步行开枪吗?
当时,这是因为类似的原因。他们发现,某些SWE基础活动可能难以解决甚至无法解决,这导致SWE Bench无法系统地评估模型编程中的自主技能。
因此,他们决定与SWE-Bench作者合作,并决定创建一个新版本,希望提供更准确的审查。
他们一起启动了一个手动注释活动,共有93位高级程序员参与过滤每个SWE-Bench测试集样本,以获得一组适当的单位测试和明确定义的问题描述。
随机选择了1699个示例,然后被标记为基础D在标准上。
例如,对问题的描述清楚吗?每个注释都有一个标签,距[0、1、2、3],并在以下内容中增加了严重性。
标签0和1表示续集;标签2和3表示严重性,表明样本在某些方面存在缺陷,应丢弃。
此外,我们通过在开发人员确定和实施解决方案所需的时间估算评论员来评估每个示例的难度。
最后,获得了500个经过验证的样本,数据集是贫困的。 “简单”子集包含196个调整不到15分钟的任务,而“硬”子集包含45个超过1小时的活动。
结果,该子集再次减少了Openai。
另一个
但是,仍然有一个值得确定的列表,这是最原始的SWE板凳。
在此列表中,Claude 4 Opus仍然征服了领先优势。
GPT-5已发布了一段时间。我想知道你是否有E类似的编程经验?欢迎在评论部分中向我们致意。
参考链接:
[1] https://www.swebench.com/
[2] https://openai.com/index/introducing-pt-5/
[3] https://www.anththropic.com/news/claude-pus- 4-1回到Sohu,以查看更多